As one of the most important agricultural commodities, corn plays a major role in global food security and sustainable agriculture. It is a staple crop in the Great Plains of the United States ( US ), where its production accounts for about one-third of global production. Accurate and timely crop mapping provides key information for […]
As one of the most important agricultural commodities, corn plays a major role in global food security and sustainable agriculture. It is a staple crop in the Great Plains of the United States ( US ), where its production accounts for about one-third of global production.
Accurate and timely crop mapping provides key information for decision-making in agricultural applications, such as monitoring crop growth and predicting yields.
Machine learning is used in the process of analyzing and classifying crop images and in forecasting crop vegetation indices.
Currently, image acquisition and classification is applied to corn crops grown in different regions of the world, resulting in a map of corn production:
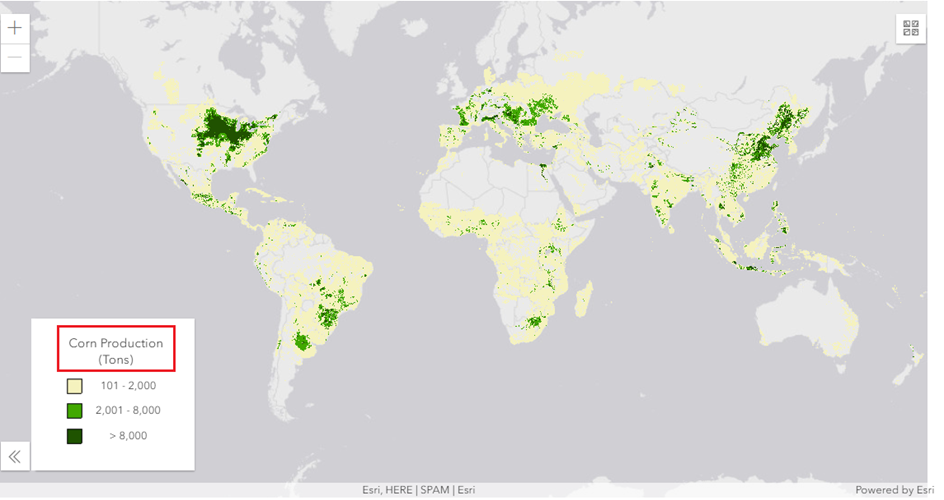
The role and importance of crop mapping.
Accurate and timely crop mapping provides key information for decision-making in agricultural applications, such as monitoring crop growth and predicting yields. In addition, the dynamics of corn planting areas are highly related to many socioeconomic measures, such as global food supply, income and welfare, and crop insurance. It is also highly important because of its use in the production of ethanol, which is included in biofuels.
Data acquisition for analysis.
Crop images acquired remotely are widely used to map large-scale crop dynamics. With the advent of massive Earth observations from various sensors and satellites, they have become the primary data sources for large-scale crop mapping, using observations from MODIS , Landsat data , Sentinel-2 and multi-source data sets from various satellites. Among these data sources, Landsat images are preferentially used in many studies because of their high resolution ( 30 m ) and long lead time (since 1970). The use of the full archive of Landsat time series data throughout the growing season is a widely used approach for finding critical information on crop dynamics at different stages of cultivation, which can show great potential for crop classification.
Image classification.
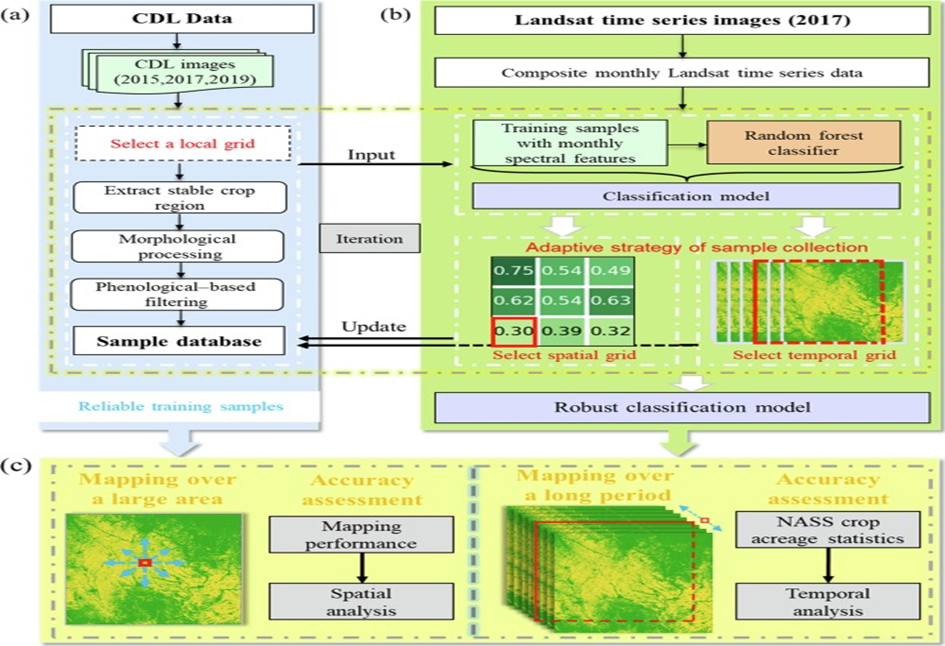
A random forest, for example, is used as a tool for crop classification.
Very important in this is the approach to training samples, which must be stable in terms of location and temporal dynamics.
Classification results can be significantly improved by using adaptive strategies in the sampling process. In particular, they can improve mapping performance in space and time, showing great potential in generating robust classification models.
The effectiveness of adaptive strategies was demonstrated by comparing them with results obtained from randomly sampled training samples.
Diagram of the data collection and classification process:
MODIS Vegetation Index Products (NDVI and EVI).
MODIS vegetation indices are produced at 16-day intervals and at multiple spatial resolutions. They provide consistent spatial and temporal comparisons of vegetation canopy greenness, complex leaf surface properties, chlorophyll and canopy structure. Two vegetation indices are derived from atmospherically corrected reflectance in the red, near-infrared and blue wavelength bands. The first, is the normalized difference vegetation index ( NDVI ), which provides continuity to NOAA’s AVHRR NDVI time series record for historical and climate applications. The second is an enhanced vegetation index ( EVI ), which improves sensitivity in dense vegetation conditions. These two indices more effectively characterize the global range of vegetation states and processes. The predicted values of these indices are used, among other things, to estimate crop productivity.
Forecasting vegetation indices.
Vegetation indices are closely related to weather conditions in the growing region. In particular, with the cumulative value of precipitation and the amount of solar radiation reaching the ground surface, as well as with humidity and temperature.
The forecast values of the indicators depend strongly on the forecasts of the weather factors themselves and the forecasts of the amount of radiation.
Based on historical data, a model of the indicator’s relationships with these factors is created, and the strength of these relationships is determined using machine learning.
The tool used in the process of determining the strength of dependencies can be, for example, neural networks.
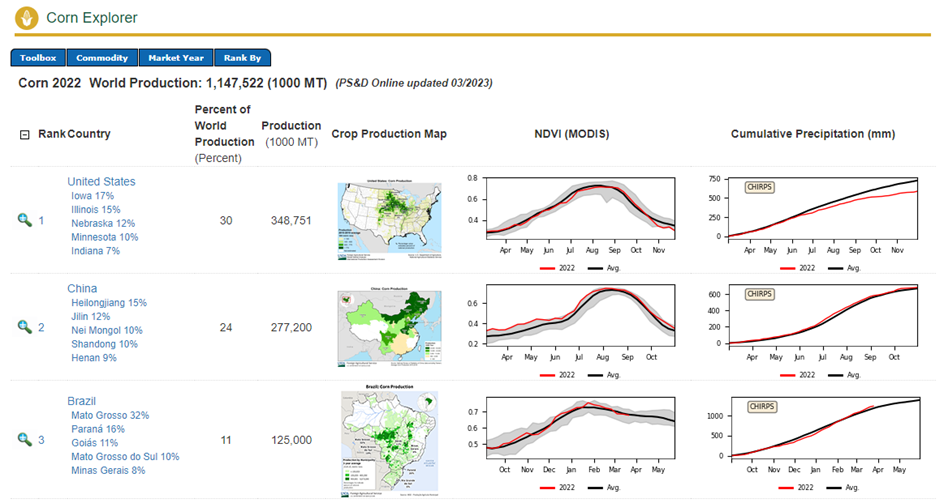
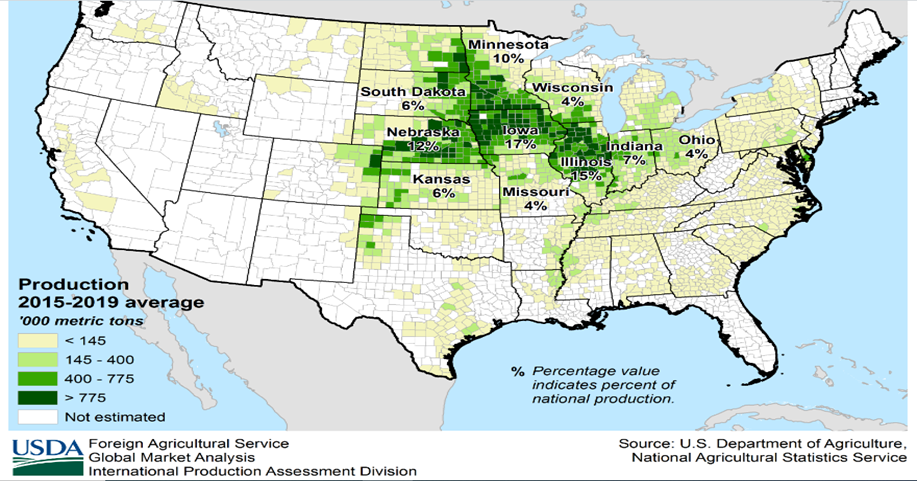
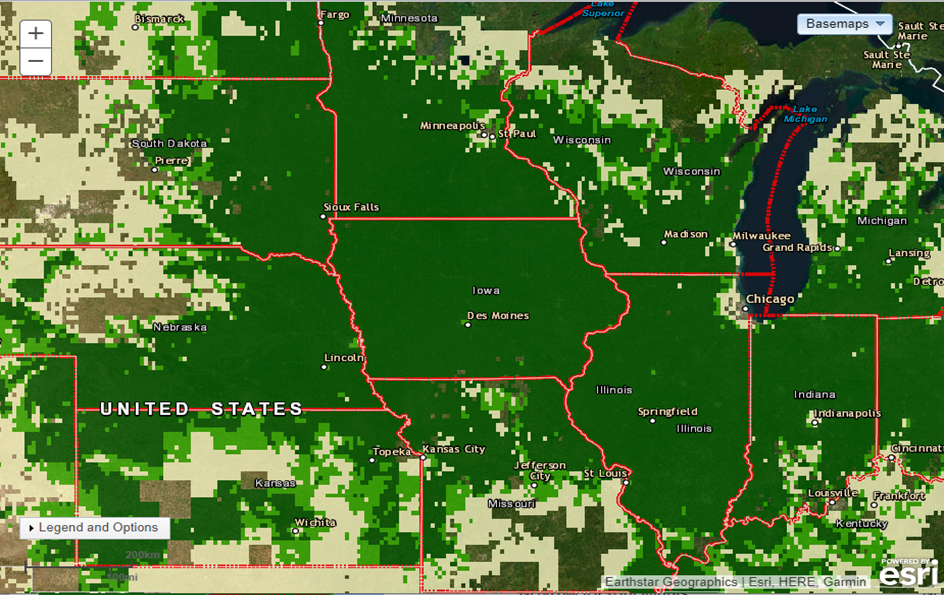
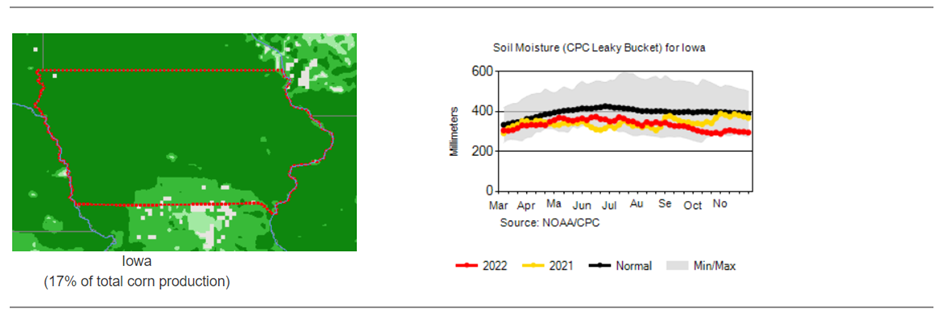
The largest portion of U.S. corn production is realized in Iowa.
Weather factors versus NDVI vegetation index – historical runs for the state of Iowa:
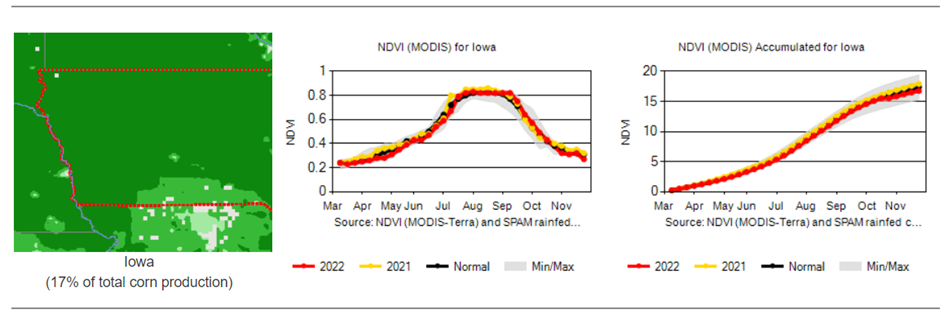
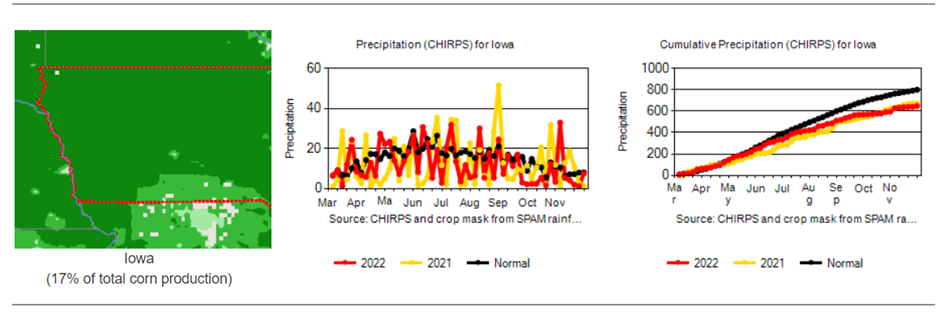
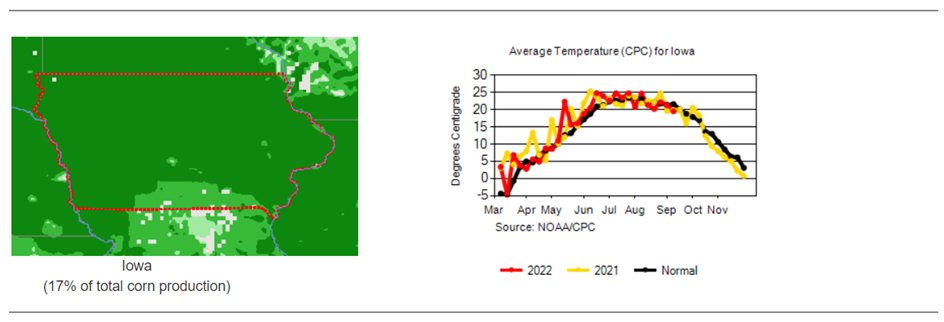
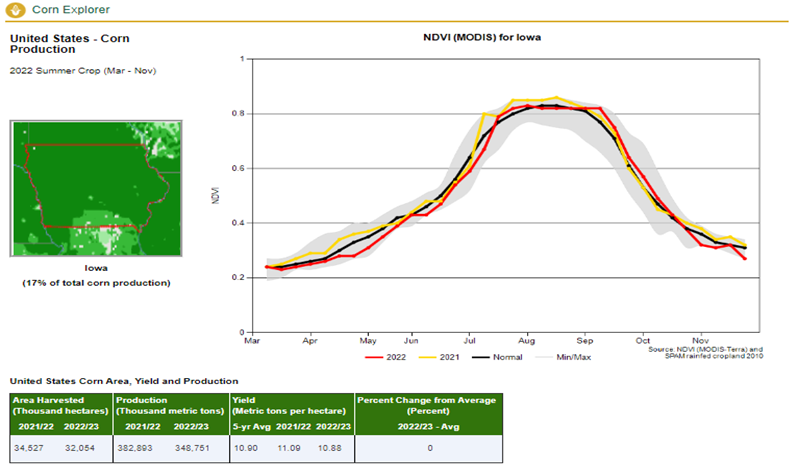
Cultivated area, volume and yield of corn production in the US:
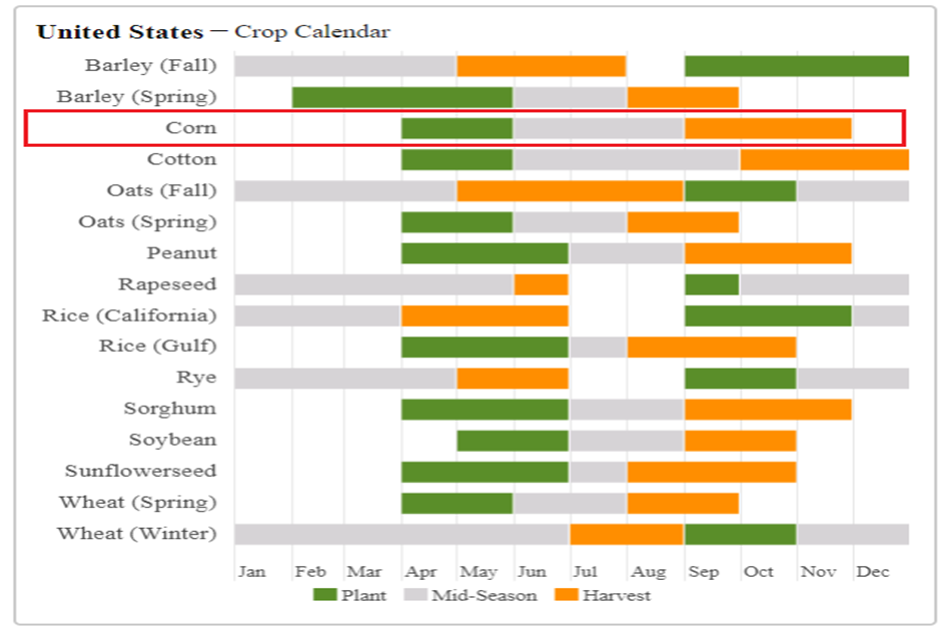
Sources:
https://www.sciencedirect.com/science/article/pii/S0924271622001691
